Imitation Learning With a Focus on Humanoids
Imitation learning has been a driver of a lot of stocks in recent times (2025). Numerous robotics companies have shown the world the potential of robots doing tasks in the real world. This rather recent surge of videos and buzz of physical AI is from the power of imitation learning from Figure, 1X or Sunday Robotics (see more in references). It is a method to show what the robot should do and make it learn to imitate those useful actions. In this article we will go over imitation learning and a short tutorial on how to collect data for your Unitree G1 humanoid robot. We will also go over training and deployment of the imitation learning policy.
Motivation & Background
Training humanoid robots to perform dexterous, contact-rich tasks is challenging because current simulators still cannot reproduce realistic friction, contact, and multi-surface interactions. As a result, reinforcement learning alone often fails to transfer effectively to real hardware. Imitation Learning (IL) provides a practical alternative by allowing robots to learn behaviors directly from expert demonstrations instead of relying on handcrafted reward functions or manually engineered controllers.
In IL, demonstrations encode the structure of the task coordination patterns, timing, and context making it well suited for high-DOF humanoids. Behavior Cloning (BC) forms the foundation of IL, mapping observations to expert actions through supervised learning. While simple and scalable, BC suffers from covariate shift when the robot drifts into unseen states. Iterative methods like DAgger address this by collecting additional corrective demonstrations, significantly improving robustness.
Overall, IL offers a reliable and scalable pathway for teaching real humanoids complex manipulation and whole-body skills that remain difficult to learn through simulation-driven RL alone.
Core Concepts of Imitation Learning
Imitation learning (IL) is a family of techniques that enable robots to acquire complex behaviors by observing expert demonstrations rather than relying on manually engineered reward functions or hand-crafted controllers. The central idea is that expert behavior implicitly encodes the structure of the task, that is, coordination patterns, contact timings, and context-dependent decisions, which the robot can learn to reproduce directly. This makes IL especially appealing in humanoid manipulation and loco-manipulation settings, where defining explicit objectives for every joint and environmental interaction is impractical. While simulators can help learn locomotion skills, in 2025, they are just not capable of mimicking the right contacts and frictions to enable effective RL-based techniques.
The most foundational IL method is Behavior Cloning (BC). In BC, a supervised learning model is trained to map observations (such as images, depth maps, joint states, and object poses) to the corresponding expert actions. It is a direct one-to-one mapping. Although BC is simple to implement and can achieve strong performance when demonstrations cover the relevant state space, it struggles with covariate shift. Small prediction errors can cause the robot to drift from the demonstrated trajectory, eventually entering states that were never seen during training. This leads to compounding errors and rapidly degrading performance when anything out of distribution is encountered. To address this limitation, DAgger-style iterative methods expand the dataset by repeatedly allowing the robot to act, querying the expert for corrections, and aggregating these new samples. This produces a training distribution that more closely matches what the robot will encounter at deployment time, significantly improving robustness. Modern IL for humanoid robots also relies on rich, multi-modal representations.
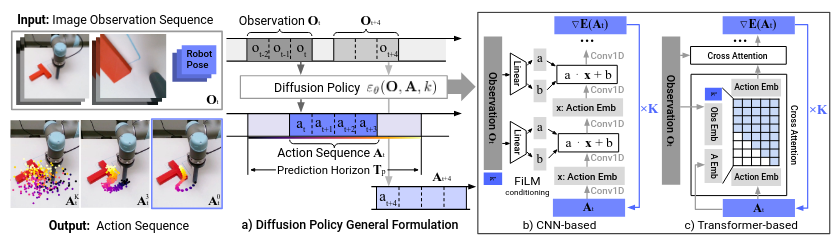
image source
Policies often combine RGB-D input, proprioceptive feedback, contact sensors (not in popular VLAs), and task-level context into a single latent embedding. Temporal information is equally important: many manipulation skills unfold over long horizons, so models frequently incorporate sequence encoders such as RNNs, Transformers, or diffusion-based temporal denoisers, see figure above. Learn more about Diffusion Policy here.
These architectures help the policy understand motion intent, anticipate future states, and execute coordinated, multi-step actions. IL can be deployed for both single-arm manipulation (e.g., grasping, reaching, insertion tasks) and bi-manual or whole-body behaviors that require coordinated control across many degrees of freedom (14 DOFs for Unitree G1’s upper body). In these high-dimensional settings, demonstration quality, coverage, and diversity become decisive factors, as the learned policy inherits the strengths and weaknesses of its training data. Consequently, robust IL pipelines emphasize careful demonstration collection, consistency checks, and dataset balancing to ensure successful transfer to real humanoid systems.
Data Collection
Overview
Humanoid imitation learning (IL) is all about teaching a robot to reproduce expert behaviors from demonstrations, instead of hand-coding controllers or rewards. In practice, the pipeline looks like this:
- Collect demonstrations via teleoperation (Apple Vision Pro controlling the Unitree G1 with dexterous hands).
- Record synchronized multi-modal data on the host machine (images, joint states, actions, timestamps, etc.).
- Convert raw logs (e.g., Unitree JSON format) into a standardized dataset format (e.g., LeRobot) so that downstream training code (GR00T, other VLA/IL pipelines) can consume it.
Tips for Collecting High-fidelity Data
Three Operator Workflow
- Having Operator A in VR, Operator B at the terminal, Operator C in front of the workspace
- Operator A should practice enough to conduct smooth and agile teleoperation
- Operator B should monitor terminals for errors, FPS drops, or connection loss
- Operator C should recover the scene after each episode of data collection
Consistency of Demonstrations
- Try to keep a consistent style of demonstrations per dataset
- Avoid long idle periods. They increase dataset size without adding useful signal
Short, repeated segments
- It’s usually better to collect multiple shorter recordings (start/stop with s) rather than one giant file
- This makes debugging and filtering specific trajectories easier later
Document Everything
For each dataset, write down:
- Date/time
- Task description
- Number of trajectories
- Any anomalies (e.g., dropped frames, partial demos)
Example (Unitree G1 with GR00T)
Below is the full pipeline we used to collect, convert, and transfer data for IL on the Unitree G1 using Apple Vision Pro teleoperation and a LeRobot-style dataset for GR00T-based training.
Data Collection
Repo: xr_teleoperate
1. Start the image server on the robot
SSH into the G1’s onboard computer and launch the RealSense image server:
ssh unitree@192.168.123.164
# password: 123
cd image_server/
conda activate realsense
python image_server.py
# You should see output similar to:
# {'fps': 60, 'head_camera_type': 'realsense', 'head_camera_image_shape': [480, 640], 'head_camera_id_numbers': ['242622070829']}
# [Image Server] Head camera 242622070829 resolution: 480 x 640
# [Image Server] Image server has started, waiting for client connections...
Once the image server is running, you can use image_client.py on the host machine to test connectivity:
cd xr_teleoperate/teleop/image_server/
conda activate tv
python image_client.py
If everything is working, you should see streamed images from the robot’s head camera on the host.
Launch the AVP teleoperation
- It’s best to have two operators:
- Operator A: wears Apple Vision Pro and teleoperates.
- Operator B: runs code on the host machine and manages recording.
- On the host machine, Operator B launches the teleop script:
cd xp_teleoperate/teleop
conda activate tv
python teleop_hand_and_arm.py --record
-
If the program starts successfully, the terminal will pause at a line like:
Please enter the start signal (enter ‘r’ to start the subsequent program):
-
Meanwhile, Operator A performs the following steps on Apple Vision Pro:
- Wear the Apple Vision Pro device.
-
Open Safari in AVP and visit:
https://192.168.168.231:8012/?ws=wss://192.168.168.231:8012
Note: This IP address should match the host machine.
3. Click **Enter VR** and **Allow** to start the VR session.
4. You should now see the robot’s first-person view in Apple Vision Pro. 3. Once VR is ready, Operator B presses **r** in the teleop terminal to start the program. 4. At this point, Operator A can remotely control the robot’s arms and dexterous hands in VR. 5. To record data:
- Operator B presses **s** in the “record image” window to **start recording**.
- Press **s** again to **stop recording**.
- Repeat as needed to capture multiple demonstration segments.
Data Conversion
Repo: unitree_IL_lerobot
1. Sort and rename raw data folders
Use the utility script to standardize and clean your data folder structure.
cd unitree_IL_lerobot
conda activate unitree_lerobot
python unitree_lerobot/utils/sort_and_rename_folders.py \
--data_dir $HOME/datasets/task_name
2. Convert Unitree JSON dataset to LeRobot format
Convert the raw Unitree JSON logs into a LeRobot-compatible dataset. This will optionally push the dataset to the Hugging Face Hub.
cd unitree_IL_lerobot
conda activate unitree_lerobot
python unitree_lerobot/utils/convert_unitree_json_to_lerobot.py
Key arguments:
-
-raw-dir
Directory of your raw JSON dataset.
-
-repo-id
Your unique dataset repo ID on Hugging Face Hub (e.g., username/task_name).
-
-push_to_hub
Whether to upload the dataset to the Hugging Face Hub (true / false, if supported in the script).
-
-robot_type
Robot configuration (e.g., Unitree_G1_Dex3, Unitree_Z1_Dual, Unitree_G1_Dual_Arm, etc.).
After this step, the converted dataset will be stored under the local Hugging Face / LeRobot cache (typically under ~/.cache/huggingface/lerobot/…).
Architecture Breakdown
Now that we have collected the data, how do we train? What do we train?
Modern imitation learning architectures for humanoid robots typically follow a three-stage design: perception, representation, and action generation. The perception module fuses multi-modal observations (RGB images, joint states, contact indicators, and task cues) into a structured latent embedding. This embedding is processed by a temporal backbone such as an RNN, Transformer, or diffusion-based sequence model to capture motion dependencies and long-horizon task structure.
The action head then maps this latent representation to motor commands, either in joint space (e.g., 14-DoF upper-body control for the case of Unitree G1) or in task space, depending on the controller interface. Architecturally, IL pipelines separate the policy model from the data-routing infrastructure, which handles real-time synchronization of images, timestamps, proprioceptive signals, and expert actions. This modular design enables clean integration with downstream locomotion and manipulation controllers and supports both offline training and online corrective data aggregation. Overall, the architecture ensures that expert demonstrations flow cleanly from raw sensor inputs to executable robot trajectories in a reproducible and scalable manner.
Nvidia’s Robotic Foundation Model
A useful conceptual framing of this pipeline is the System-1 / System-2 hierarchy in NVIDIA’s Isaac GR00T model.
The ability to process large volumes of data and generate responses swiftly mirrors a type of human cognition described by psychologist Daniel Kahneman in his book “Thinking, Fast and Slow”. Kahneman identifies two types of thinking systems in human cognition: System 1 and System 2 (see Figure below).
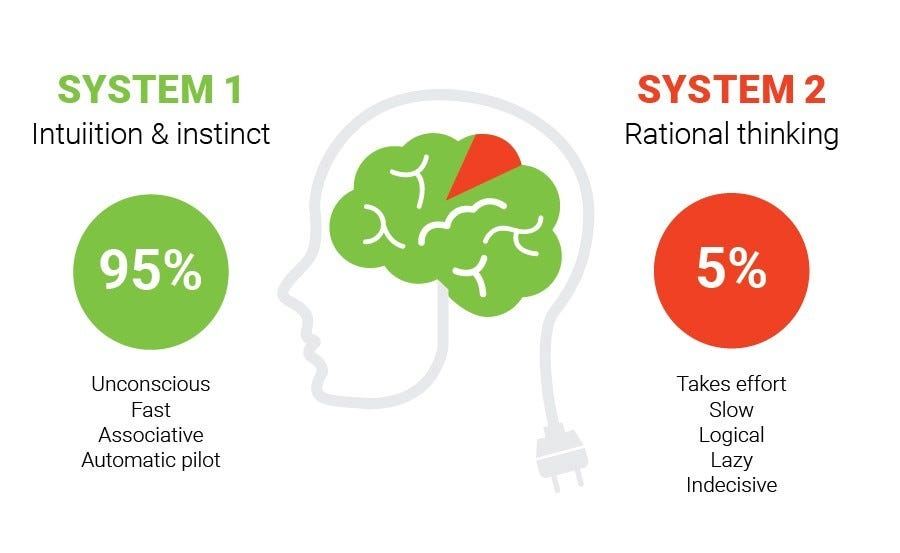
image source: Nguyen Ha Thanh Bridging Generative Models and System 1 with System 2: link
System-1 corresponds to the fast, reactive control policy - a compact, low-latency model that outputs robot actions directly from processed observations. It is optimized for real-time behavior cloning or diffusion-policy execution and serves as the “intuitive” control layer that runs on the robot. System-2, on the other hand, operates at a higher level of abstraction: it interprets language instructions, reasons over goals, selects subtasks, and organizes long-horizon behavior.
Whereas System-1 executes moment-to-moment motor control, System-2 provides planning, task decomposition, and symbolic grounding. In an imitation-learning context, System-1 is trained directly on expert trajectories, while System-2 may be trained on demonstration annotations, teleoperation episodes, or scripted task descriptions.
The figure below demonstrates NVIDIA GR00T’s System1-System2 architecture:
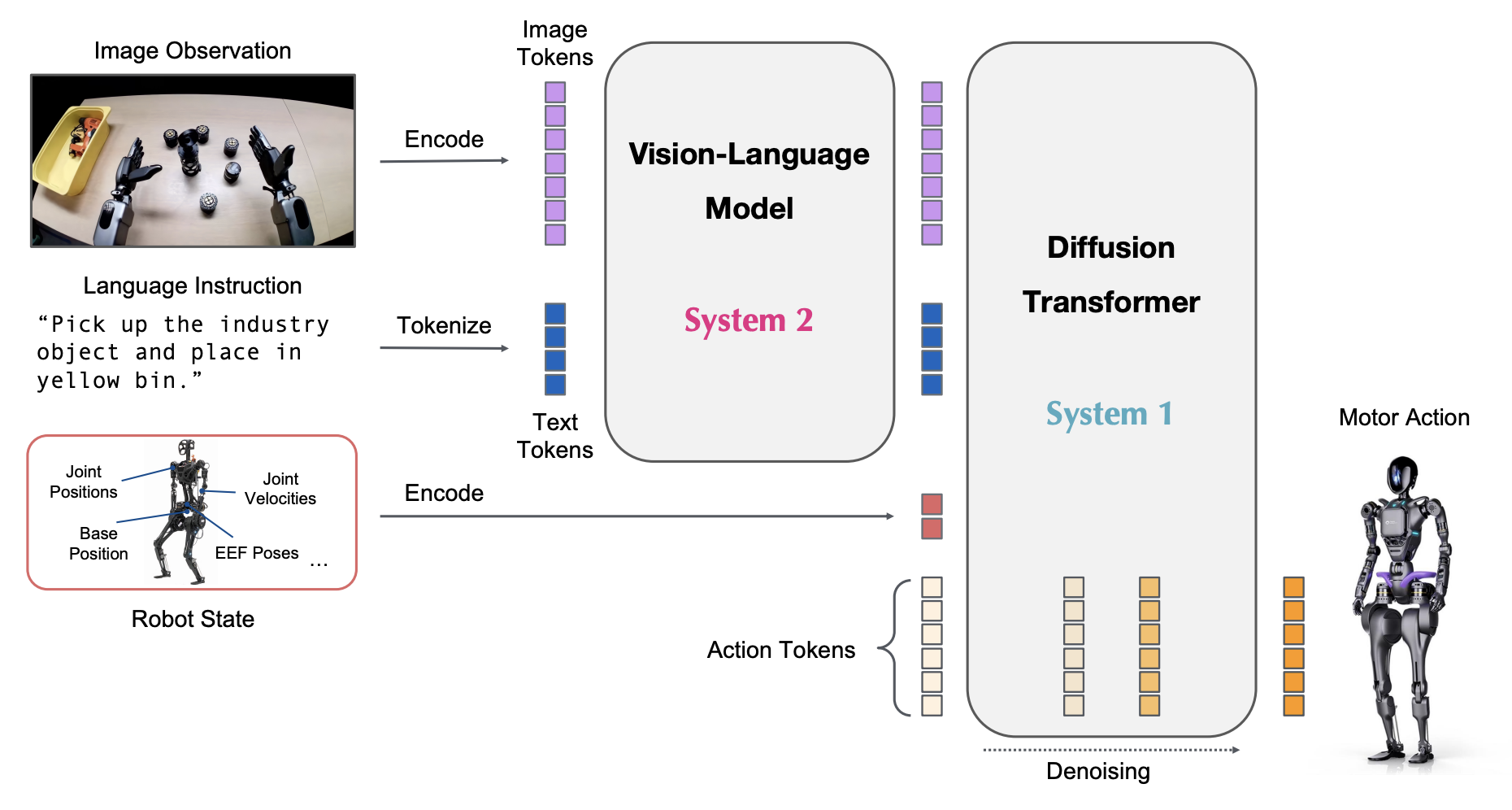
image source: GR00T paper
Diving deep into the sub-components:
A central component in NVIDIA’s GR00T stack is EAGLE, a vision-language model optimized for robotic perception. Unlike generic VLMs, EAGLE uses a multi-scale CNN–ViT hybrid encoder tailored for depth-augmented RGB inputs, producing manipulation-ready visual embeddings that capture affordances, object poses, and fine-grained contact geometry. These embeddings feed directly into the representation module, forming the perceptual foundation for downstream control.
For action generation, GR00T uses a Diffusion Transformer (DiT) as its System-1 policy. The DiT models action generation as a conditional denoising process: expert actions are perturbed with noise during training, and the transformer learns to iteratively denoise them using the fused observation embedding. This enables the policy to represent multi-modal action distributions, smooth trajectories, and complex synergies across the robot’s high-DOF limbs. When deployed, the DiT produces clean, low-latency motor commands suitable for real-time control of the Unitree G1’s 14-DoF upper body or full loco-manipulation stack.
On top of this reactive controller lies System-2 GR00T, the deliberative reasoning layer. System-2 operates at a higher abstraction level, interpreting language instructions, selecting subtasks, sequencing long-horizon behaviors, and grounding goals in the current scene. In an IL context, System-1 is trained directly on expert trajectories, while System-2 leverages demonstration annotations, teleoperation episodes, or scripted task graphs. Together, they form a hierarchy where System-2 decides what to do, and the DiT-based System-1 policy determines how to execute it.
This modular architecture cleanly separates perception, reasoning, and control, making it easier to integrate with locomotion policies, motion planners, and real-time data-routing infrastructure. As a result, expert demonstrations can flow reliably from raw sensory input to stable, executable robot trajectories, supporting both short-horizon manipulation and complex multi-step humanoid behaviors.
Comparison to Diffusion Policy
While both GR00T’s System-1 controller and classical Diffusion Policy use diffusion-based action generation, GR00T extends the idea in several important ways. Traditional Diffusion Policy models actions as short-horizon trajectories conditioned on observations, but they operate as single-level controllers with no built-in mechanism for task planning, subgoal reasoning, or language grounding. GR00T’s DiT, in contrast, is embedded inside a hierarchical architecture: a powerful System-2 module handles task decomposition, instruction following, and semantic grounding, while the DiT functions as a fast reactive System-1 controller. Additionally, Diffusion Policy typically relies on convolutional or simple transformer encoders, whereas GR00T leverages EAGLE, a robot-specialized VLM that provides richer multi-modal embeddings and stronger 2D/3D scene understanding. As a result, GR00T is able to scale beyond short manipulation tasks to long-horizon, language-driven humanoid behavior, while maintaining the smooth trajectory generation and robustness that diffusion models are known for.
Conclusion
Taken together, the System-1/System-2 hierarchy, EAGLE’s rich visual embeddings, and the DiT-based low-level controller provide a principled blueprint for scaling imitation learning to real humanoid robots. By separating fast motor control from high-level reasoning, and grounding both in a strong perception backbone, GR00T-style architectures overcome many of the historical limitations of IL, such as covariate shift, poor generalization, and ambiguity in long-horizon tasks. This layered design ultimately enables humanoids like the Unitree G1 to execute robust, interpretable, and multi-step manipulation behaviors directly from demonstrations, making imitation learning a practical, data-efficient foundation for next-generation embodied intelligence.
Deployment in Humanoid Robotics
We sincerely recommend you to look at the sim2real deployment pipeline of FALCON: Project Webpage
The code is open-sourced at: Official Implementation of FALCON
Summary
Imitation learning has emerged as the dominant approach for teaching humanoid robots complex manipulation tasks, bypassing simulation’s limitations in modeling realistic contacts and friction. This article covers both the theoretical foundations and practical implementation of IL for humanoid platforms. We explain core IL concepts including Behavior Cloning and DAgger, which address covariate shift through iterative data collection. The article provides a complete data collection pipeline for the Unitree G1 using Apple Vision Pro teleoperation, including best practices for multi-operator workflows, data synchronization, and conversion to standardized formats.
The architecture section examines NVIDIA’s GR00T foundation model through Kahneman’s System-1/System-2 framework: System-1 provides fast reactive control via a Diffusion Transformer policy, while System-2 handles high-level reasoning and task decomposition. EAGLE’s vision-language encoder bridges perception and action, enabling GR00T to scale beyond classical Diffusion Policy to long-horizon, language-driven behaviors. For deployment guidance, we recommend examining FALCON’s sim2real pipeline. Together, these components demonstrate how IL has matured into a practical foundation for teaching humanoids complex whole-body skills that remain intractable for simulation-based reinforcement learning alone.
See Also
Further Reading
- Concept of thinking systems in human cognition
- Figure AI’s robot sorting packages youtube
- 1X performing human-like long-horizon tasks youtube
- Sunday Robotics performing distinct household tasks youtube
References
- Bjorck, Johan, et al. “Gr00t n1: An open foundation model for generalist humanoid robots.” arXiv preprint arXiv:2503.14734 (2025). GR00T paper
- Zhang, Yuanhang, et al. “FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation.” arXiv preprint arXiv:2505.06776 (2025). FALCON paper